Working on projects in the Big Data area, using the current technologies PySpark, Apache Spark, Apache Kafka, Azure DataFactory, Databricks, Google Cloud Platform (GCP), Microsoft Azure.
I consider myself extremely dedicated, focused on goals. I am self-taught, adaptable and flexible to new environments and new technologies.
Always seeking for delivering best results to the business.
University
B.S in Computer Science from USJT - 2020
MBA in Data Engineer from IGTI - 2021-2022
Living in
São Paulo, Brazil
Portfolio
Here you can find my developed projects: applications, mobile, frameworks, awards , certifications.
I hope you enjoy.
Data Engineer Pl. Working on projects in the Big Data area, using current technologies PySpark, Apache Spark, Apache Kafka, Azure DataFactory, Databricks, Google Cloud Platform, Microsoft Azure at
BlueShift Brasil
Dez 2020 - o momento · Calculando...
Data Engineer Pl. Working on projects in the Big Data area, using current technologies PySpark, Apache Spark, Apache Kafka, Azure DataFactory, Databricks, Google Cloud Platform, Microsoft Azure at
BlueShift Brasil Developed projects Natura - Performance in projects with the big data team:
Development and maintenance of data pipeline components, primarily for data ingestion and data quality.
Technologies:
Apache Airflow
Pyspark
Jenkins
Hadoop (Hive, HDFS, Yarn)
AWS (EMR, S3, Redshift, Glue)
Oracle, MySQL, SQLServer
Databricks
Workflows
Catalog Explorer
Product
Hive metastore
Workflows using the Databricks environment to orchestrate ETL (Extract, Transform, Load) processes and data ingestion in Big Data environments. I utilize Databricks as the primary platform for building and executing data ingestion jobs, ensuring high availability and scalability. Additionally, I have experience in creating data products through the Catalog Explorer and Hive Metastore, enabling me to implement robust and efficient solutions for managing and cataloging metadata in distributed storage environments.
Set 2022 - o momento · Calculando...
Data Engineer Jr. Working on projects in the Big Data area, using current technologies PySpark, Apache Spark, Apache Kafka, Azure DataFactory, Databricks, Google Cloud Platform, Microsoft Azure at
BlueShift Brasil Developed projects Natura - Performance in projects with the big data team:
Development and maintenance of data pipeline components, primarily for data ingestion and data quality.
Technologies:
Apache Airflow
Pyspark
Jenkins
Hadoop (Hive, HDFS, Yarn)
AWS (EMR, S3, Redshift, Glue)
Oracle, MySQL, SQLServer
Databricks
Workflows
Catalog Explorer
Product
Hive metastore
Workflows using the Databricks environment to orchestrate ETL (Extract, Transform, Load) processes and data ingestion in Big Data environments. I utilize Databricks as the primary platform for building and executing data ingestion jobs, ensuring high availability and scalability. Additionally, I have experience in creating data products through the Catalog Explorer and Hive Metastore, enabling me to implement robust and efficient solutions for managing and cataloging metadata in distributed storage environments.
Mar 2021 - set 2022 · 1 ano 7 meses
Data Engineer Jr. Working on projects in the Big Data area, using current technologies PySpark, Apache Spark, Apache Kafka, Azure DataFactory, Databricks, Google Cloud Platform, Microsoft Azure at
BlueShift Brasil Developed projects Client Netshoes / Magalu - Performance in projects with the big data team:
Development of ETLs in pyspark using Databricks and Dataproc, using data from BigQuery, sqldw, and google datalake (GFS). Creation of routines for sending encrypted data. Development of procedures and views in Oracle and SQL DW databases.
Mar 2021
Data Engineer Trainee - Big Data & AnalyticsI am currently specializing in the area of Big Data & Analytics at
BlueShift Brasil Developed projects
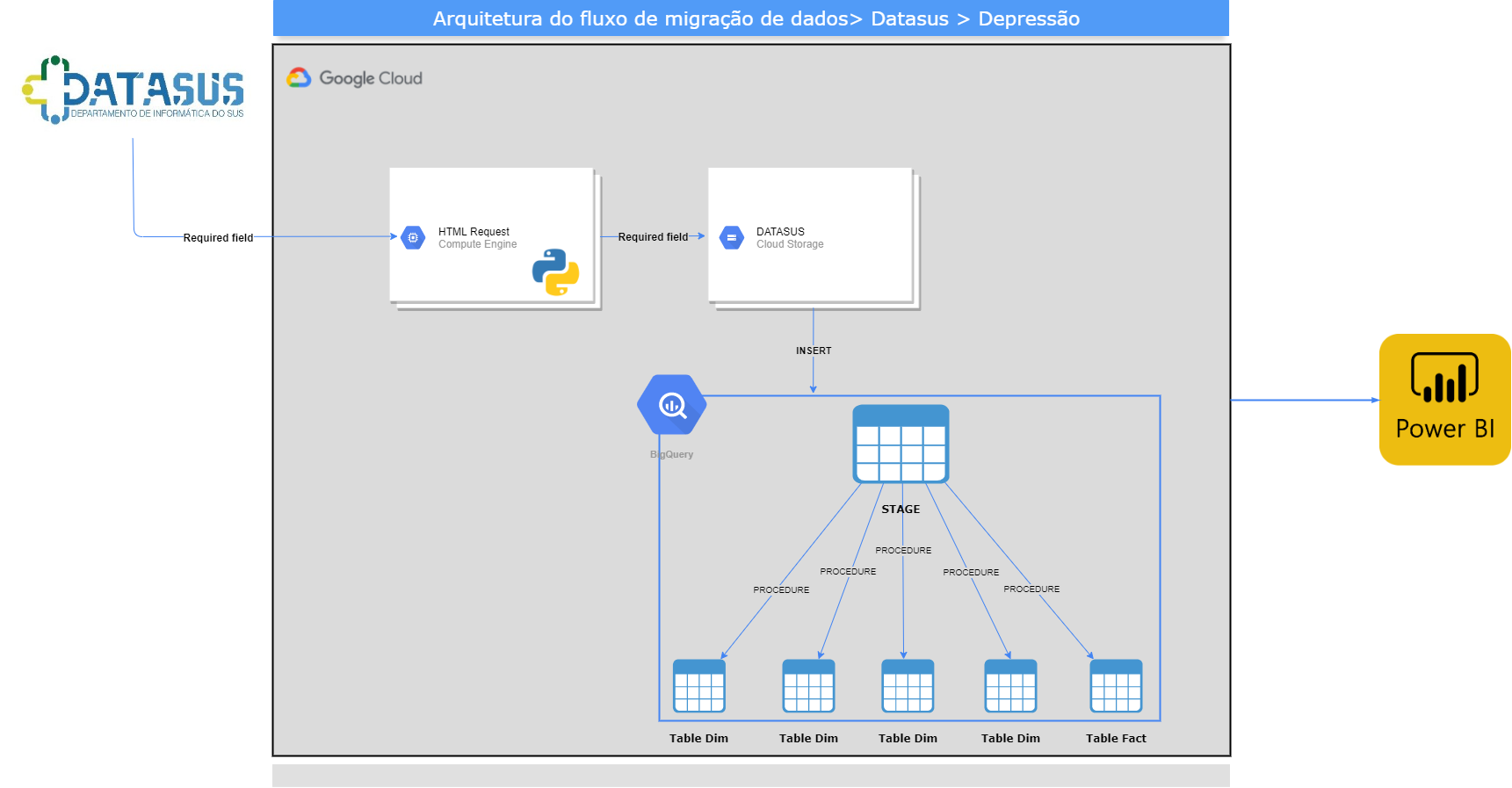
Depression: Integrated project that consists of collecting data on the theme of Depression, which is at the base of DATASUS, based on the data extraction process (ETL), through the Google Cloud Platform, the flow that was developed uses the Computer Engine to carry out the treatment of the base via Python and Cloud Storage (GCP), to make the storage of the treated base and, finally, BigQuery for SQL queries, finalizing the infrastructure of the base.
Dec 2020 - mar 2021 4 meses
Develop low platformworkflow applications for
information, flexible rates, creation of process dashboards
internal areas, and segmentation of product information bases and
services, using the Access tool to develop the SQL data, and
VBA codes in
Bradesco S.A
2018 - 2020
Information Technology InternshipTechnical support to users and customers, configuration of application databases: installation, configuration, services and monitoring (e-mail, Office, ERP and client software), Install and configure micros, Install and configure networks, Create spreadsheets electronic reports and miscellaneous reports, Support IT infrastructure, solving problems in systems and programs.
Fundação para Conservação e Produção Florestal do Estado de São Paulo
2017 - 2018
Skills
Always studying for Implementing the most current methodologies and techniques.
You can share information about yourself with the community on GitHub by creating a profile README. GitHub shows your profile README at the top of your profile page.
Contact
Do you have any suggestions, requests or do you want to talk about something, write me a message or find me on social networks.
Thank you!
Park Pay Go
Parking Payment and Control System
Technical vision of the Project:
Our system is based on rest communication, where we use 3 different languages: Flutter, Angular, Spring, where Flutter and Angular communicate with spring boot, so we can separate the communication between Front-End and Back-End.
For the payment we used Mercado Pago api. ***
for more information visit the link
Mercado Pago API
Analytical View of the Project:
We found unnecessary queues at car parks to make payment, especially during peak hours, so we saw an opportunity to improve this dynamic by facilitating both the customer and the establishment, implementing a mobile application that facilitates payment and thus avoiding queues.
#ParkPayGo #Praticidade #Facility #ChannelParkPayGo #Parking
*** Understand more about the payment method, watching the video.
Date: January 2020
Client: Universidade São Judas Tadeu
Category: Final Paper
Bradesco
Developed Projects
Developed projects
Project Name: Current Account Incorporation
Low-platform application designed to perform
capturing information from / to ex-HSBC accounts for Bradesco from UOL
and Folha da Manhã.
Project Name: Commercial Actions - Workflow Application
Workflow developed in access, makes the management of
database containing information on fees charged, return on shares
opportunities to attract new Customers, such as the Single Rate, Cash Offer,
Super Cash Offer, Conquest Condo, IGPM (Retail, Wholesale), Multipag.
Used for the monthly control of the Commercial Actions Control Dashboard,
such as the volume of Client Negotiations participating in shares
commercials arriving at DCPS; Evolution of Tariff Revenue of these customers over the months per commercial action, as well as quantity
and charged events.
Project Name: Automatic Debit Project
Low platform no access (VBA) application, for
make changes to indicator services, capture indicators, capture
contract and register trading in the new wallet, spread
wallet from old to new, and change in floating.
Project Name: Opening an MEI Account
Low MEI Account Opening Platform Application
by Bradesco Net Empresa Celular, where the application makes inquiries
accounts that opened negotiations, makes the entire process of
consultation, contract capture and alteration of tariff data, generating
6-month exemption, at the end of the process the system generates a
Excel dashboard report, which is used to analyze the
oversight.
Date: August 2018 - July 2020
Company: Bradesco S.A.
Category: Development
Programming Marathon
Universidade São Judas Tadeu
1
st
Place - Universidade São Judas Tadeu - Programming Marathon Competition 2018
Date: October 2018
University
Category: Marathon
Certificate of Achievement
Jonathan Mota
April 2021
Data Engineering with Databricks
April 2021
Fundamentals of Structured Streaming
April 2021
Introduction to Apache Spark Architecture
April 2021
Google Cloud Fundamentals
April 2021
Creating New BigQuery Datasets and Visualizing Insights
September 2020- 2022
Kanban Foundation KIKF, Kanban Institute
August 2020-2022
DevOps Essentials Professional DEPC, CertiProf
July 2020
AWS Academy Cloud Foundations in Portuguese, AWS Academy
June 2020
Big Data Analytics: Opportunities, Challenges and the Future, Griffith University
June 2020
Big Data Fundamentos 2.0, Data Science Academy
June 2020
Inteligência Artificial Fundamentos, Data Science Academy
June 2020
Introdução à Ciência de Dados 2.0, Data Science Academy
June 2020
Scrum Foundation Professional Certificate, CertiProf
October 2018
Maratona de Programação, Universidade São Judas Tadeu
May 2018
Fundamentos do Salesforce, Avanxo
April 2018
Introdução à Linguagem SQL, Impacta Tecnologia
April 2018
Introdução à Lógica de Programação, Impacta Tecnologia
March 2017
Rede Wireless , CIEE - Centro de Integração Empresa-Escola
to view certificate click on
Awards
August 2019
XÁ COMIGO
XÁ COMIGO ,It is a campaign that bradesco created internally, so that people who had a positive attitude could change something within the department.
Client: Bradesco S.A.
Category: Campaign XÁ COMIGO
January 2020
HONORABLE MENTION
Honorable Mention for work Parking Control and Payment System "Park Pay Go".
EXPOSAOJUDAS
Teacher Nelson Aguiar
Category: Final Paper
DATASUS DEPRESSION
Extraction process (ETL), Jupyter Notebook, GCP, BigQuery
Project Architecture
This document aims to detail the procedures performed for the development of the Integrated Project which consists of collecting data on the theme Depression found in the DATASUS database, based on the data extraction process (ETL), through the Google Cloud Platform, the flow that was developed uses Computer Engine to perform the treatment of the database via Python and Cloud Storage to store the treated database and finally, BigQuery for SQL queries, finalizing the infrastructure of the database
to view project at github click on
Date: March 2021
Client: BlueShift
Category: Extraction process (ETL), Jupyter Notebook, GCP, BigQuery